消息称OpenAI解雇奥特曼的导火索是可能对人类造成威胁的Q-star,它具体是什么?

About
我来说一下我对于这个算法的理解吧。
注:不一定正确的,因为我不是openai内部人员。
我认为Q star和LLM模型的最大区别就是支持的问题的复杂度发生了改变,从只能支持有限复杂度变成了支持无限复杂度。
在LLM模型中, 对于一个输出再经过了一定长度的网络之后,那么一定会输出答案。
但是很明显,有限复杂度的GPT4无法回答出更长复杂度的问题。
因此即使是GPT4也无法在不借助计算器的前提下完成3213546510*251202102。
类似于数学问题或者更为现实的问题,如果无法使用python建模,那么GPT4输出的答案就会语无伦次。因为GPT4如果可以回答出超过它所支持的复杂度的回答那么就违背了信息论的定理。
但是我们可以使用langchain来实现上述的乘法,我们让它分解到个位数相乘,然后再分解为个位数相加,最终输出。
我们可以采用langchain这种迭代的方式来支持回答更为复杂的回答,但是这种非原生的方式存在效率的问题。
每一个网络深度都代表一次抉择,但是抉择99次也不能解决需要计算100次的简单问题。
下面为示意图
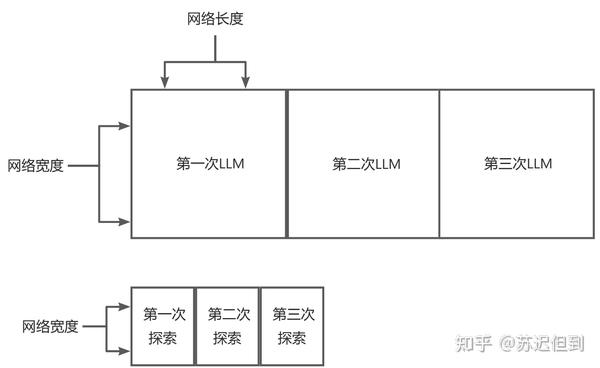
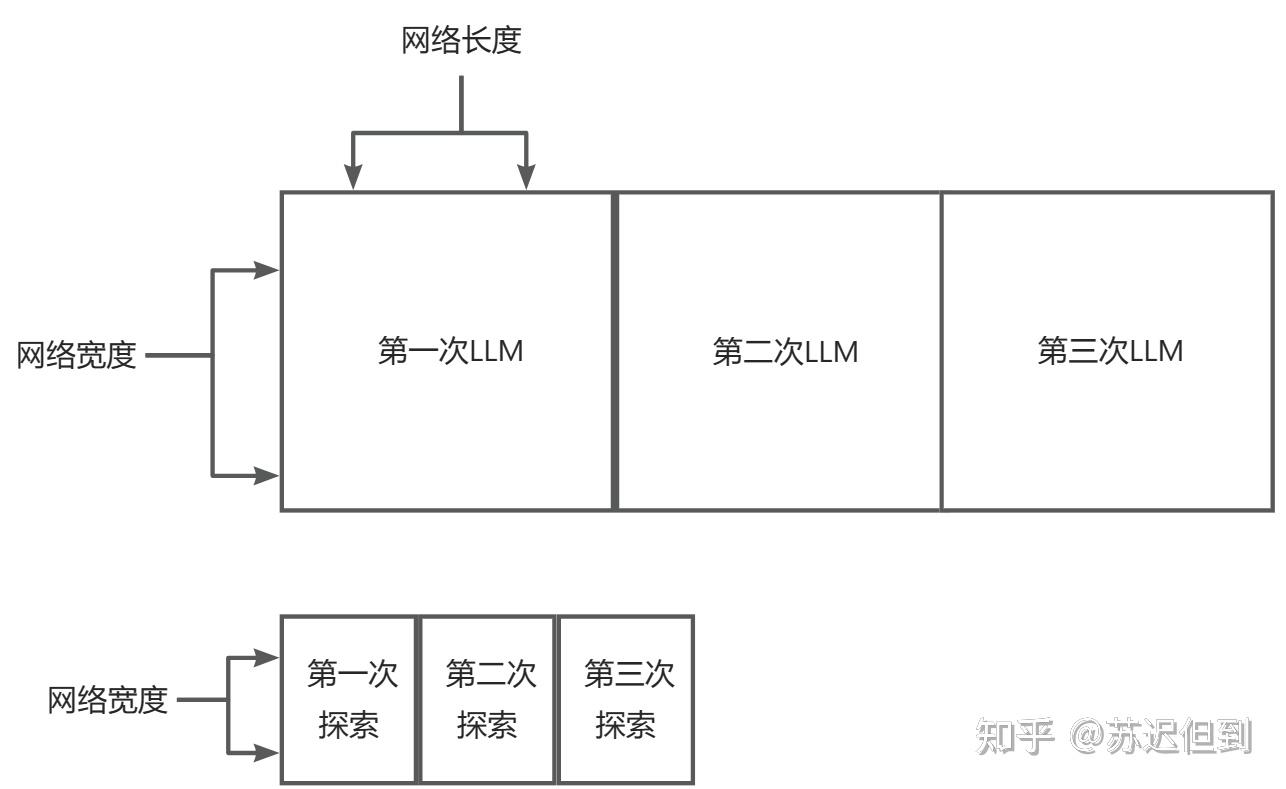
在Q star的网络中会采用更小的网络宽度和网络深度,但是采用的是寻路算法这种反复答案的迭代来解决很复杂的问题。
在Q star的理论中,所有的数学问题(更广泛的观点是认为所有的问题)都是由一组基础的数学命题组成的向量。
而解答过程就是找到这个向量。
如果这个向量的长度很长,那么就需要Q star每一步都依靠直觉找到下一步的解法。这个过程就非常类似于人的选择。从而Q star这个算法就非常类似于人类的思维。
然后就是训练过程,训练过程的话可能是一开始是反复生成5,6步的数学命题,当准确率或者运行时间等指标达到要求,再逐步增大数学命题的向量的长度,并相应的适当的增大网络宽度。
我把这个说法给别人说了之后,它们说如何定义定理的价值函数。我个人观点认为它不存在命题的价值函数,所有的命题是等价的,它是命题解答算法,不是命题生成算法。
而价值函数应该主要集中在运行时间(即找到答案的长度)这一点,也许一开始的算法会兜兜转转,一个5步才能解决的算法,最后30步才解决,那么它的价值就比较低。
所以看上去Q star类似于一个真正的思考算法,它会随着问题的复杂而思考更久,这才是符合第一性原理的算法。