有没有人解释下Sora原理?

About
我一开始以为会是3d to 2d。如果是3d to 2d那么才是真正的世界模型。
但是狗的视频让我感觉又不是了。
我个人猜测实现sora产生魔力的原理在于帧与帧的之间连续性。
这里面应该有一个人工完成的先验函数或者小模型,这个小模型主要是用来判断连续的两帧是不是在同一个视频中生成的。(这里的连续两帧不一定是具体的物理上的两帧,取决于openai的抽取参数,抽取参数可以为1s,也可以为1/24s)
因为目前很多ai视频的连续性有很大问题,通过这个先验函数可以将模型的连续性训练的很好。
我们可以证明任意连续两帧不在同一个视频的概率为无穷小量的话,那么1440帧同样也是在同一个视频。(无穷小量的n次方同样也是无穷小量)
当然事实上,肯定不是无穷小量。但是也是一个确切的值,而这是一个指数损失问题,当视频内容足够长的时候可能会使得画面失真。
背后的真实情况是gpt4生成未来60s中的每一秒的描述词,然后a模型生成相应的相邻每s的照片,然后再用b模型生成中间照片。(也有可能是专门的剧本算法。)
通过训练帧与帧的连续性的好处在于无论视频内容是否合理,产生的视频都不会带给人割裂感。
而视频的剧本和内容变化,是一个比较长的时间跨度或者可以说是信息密度极低的。如果仅靠视频标题,来从视频中学习60s所产生的内容变化,那么信息密度太低了。
即使对于人类而言,往往也是先生成视频帧内容,然后再生成画面样本的。
因此该模型里面分为两个模型是较为合理的。
最后再总结一下,sora分为两个模型
剧本模型和画面生成模型,而画面生成模型可能包含平滑描述词生成模型和平滑图片生成模型。
其中平滑描述词生成模型包含两个输入参数:上一帧图片和描述词。一个输出参数:该帧图片。
而平滑图片生成模型的工作目的是两张图片生成中间的插值图片。
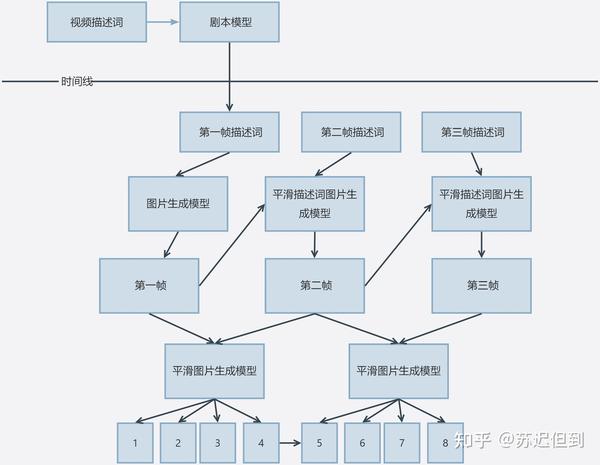
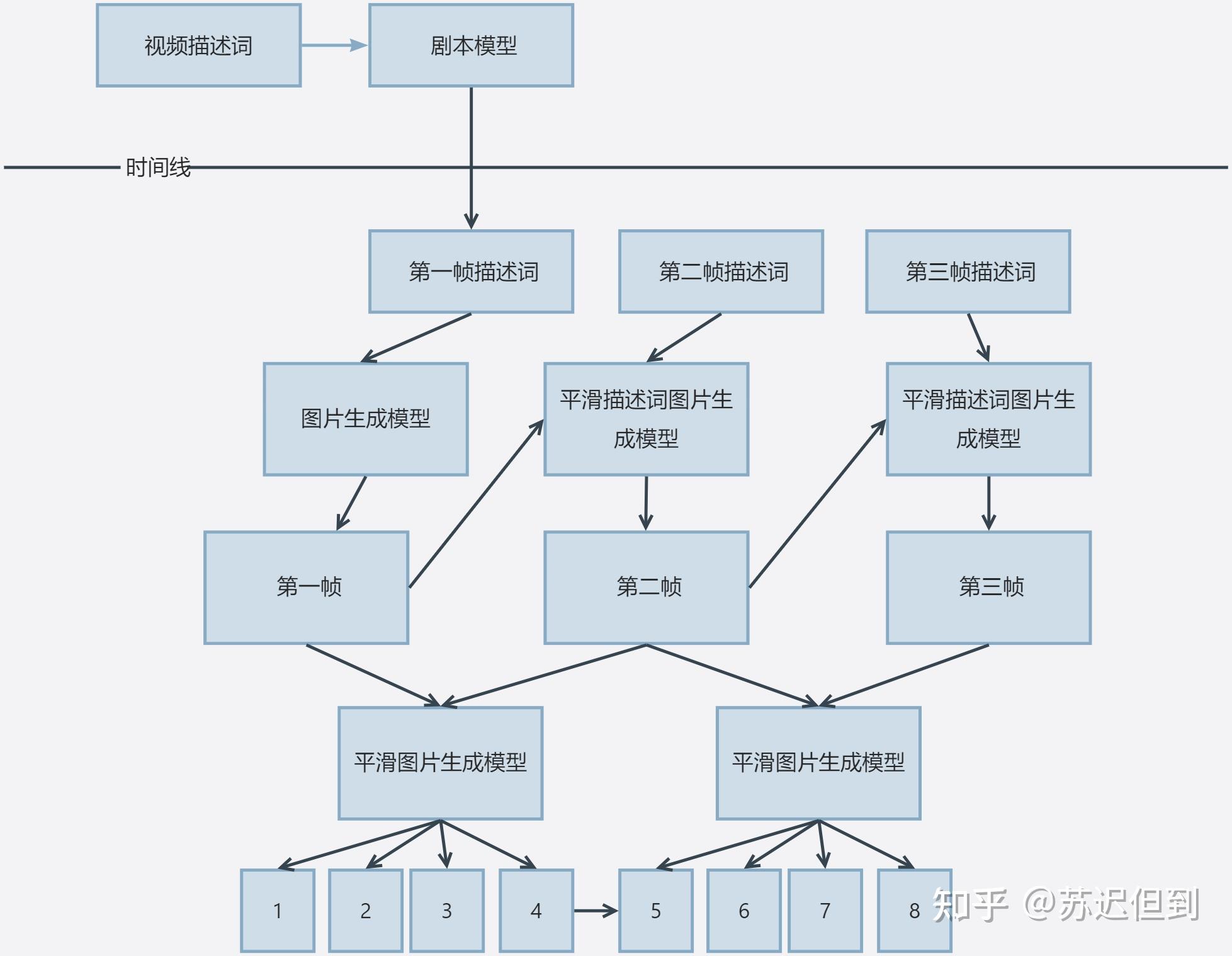
如果真的按照刚刚所说的流程的话,那么目前剧本模型和平滑图片生成模型现在都已经比较完善了。
最大的问题还是平滑描述词生成模型。而这个需要大量的真实视频作为对抗训练,从而充分学习真实视频所蕴含的连续性是什么?
当充分学习之后,可以涌现出对3D世界的部分理解和相应的物理逻辑。
例如99.9%的视频杯子悬空都会掉下去从而出现模糊或者像素向下移动,那么就意味着加速度,模型看上去就学习了重力等等。
至于这算不算世界模型,还要另外一说。